Odborná sekce
Využití umělé inteligence pro řízení Big Data úložišť
01.09.2020, 15:30
Big data úložiště lze považovat za hlavní a zároveň klíčový prvek IT infrastruktury, protože pracuje s tím nejcennějším, co v IT světě máme – s uloženými daty. Selhání systémů poskytujících data nebo jejich nedostupnost, byť jen na několik minut, mívá často katastrofální dopady na celou infrastrukturu. V rámci společného projektu výzkumu 3S.cz a VUT Brno v programu „TRIO“ představujeme Expertní systém pro automatickou analýzu a řízení big data úložišť výrobních společností.
V současné době jsou sice přísné požadavky na zabezpečení a dostupnost dat již dobře zvládnuty, ale stále zůstávají velké mezery v tom, jakým způsobem lze zabránit poruše nebo nečekanému výpadku storage systémů. Nejčastěji využívaným způsobem jak takovému kolapsu předejít, je analýza zdraví systému. Pověřený specialista vyhodnocuje nejrůznější statistiky shromážděné vždy za nějaké období v čase (např. vytížení diskových kontrolérů, vytížení disků, vytížení portů atd.) a následně provede analýzu těchto trendů. Tento způsob je schopen odhalit a reagovat na událost, která již nastala. V současné době zatím ale chybí vyšší stupeň analýzy, která by předpovídala vývoj zdraví systému pro nadcházející období, čímž by upozornila na budoucí výkonové problémy a tak by se předešlo případným výpadkům systému.
Ve spolupráci s výzkumným centrem SIX na VUT v Brně pracuje společnost 3S.cz, s. r. o. v rámci několikaletého projektu vznikl produkt, který je určen pro analytiku a řízeni Big Data úložišť na základě využití algoritmů umělé inteligence. Cílem projektu bylo vytvořit řešení, které dokáže pomocí automatické analýzy běhu systému rozpoznat nestandardní chování, s dostatečnou rezervou předpovídat přetížení a navrhnout na takto vzniklou událost adekvátní reakci, případně bude schopno vhodným způsobem se z poruchy či chyby rovnou zotavit.
Incident Degradace kvality služeb Big Data úložiště
Za incident v rámci datového úložiště je považována situace, kdy aktivita uživatelů úložiště či interní procesy v rámci samotného big data úložiště způsobují situaci degradace kvality služeb.
V situaci degradace kvality služeb je hlavním posláním expertních systémů nejrychlejším možným způsobem identifikovat hlavní příčinu problémů a vyřešit nákladné problémy spojené s degradací kvality služeb – SLA.
Krom toho samotná povaha expertního systému s využitím algoritmů strojového učení může na základě trendů výkonu big data úložiště v průběhu času proaktivně vyladit výkon pro zlepšení efektivity zdrojů a optimalizaci zkušeností koncového uživatele. Hloubka pokrytí v kombinaci s přístupem k historickým trendům a základním liniím zjednodušuje analýzu korelováním výkonu úložiště s výkonem aplikace a sítě, což pomáhá lépe definovat hlavní příčinu problému.
Definice problému identifikace příčiny degradace výkonu Big Data úložiště
Současné Big Data úložiště se díky vývoji posledních let staly velmi komplexními systémy. Samotné úložiště již zdaleka není prostým RAID systémem, kde data jsou zabezpečena XOR mechanismem paritních vektorů. V samotném Big data úložišti běží na pozadí mnoho podpůrných procesů, které umožňují organizacím řešit velmi efektivními metodami:
- Ochranu dat pomocí diskových klonů a snapshotů
- Optimalizaci rozložení dat pomocí automatického tieringu
- Efektivní čerpání logické kapacity nezávisle na fyzické kapacitě pomocí tenkého provisioningu
- Kapacitně šetřící funkce komprese a deduplikace
- Health-check mechanismy kontroly konzistence dat a stavu datových médií
Uvedených několik bodů je pouze velmi stručným výčtem mnoha desítek až stovek procesů, které jsou inherentně zabudovány v systémech Big Data úložišť.
Tato míra komplexnosti zároveň definuje i základní problém monitoringu současných systémů Big Data úložišť. Existuje řada řešení, které dokáží graficky zobrazit utilizaci komponent Big Data úložiště a provozní objemy v jednotlivých jeho perimetrech. Nicméně vzhledem ke komplexnosti mnoha souběžně se odehrávajících procesů Big Data úložišti neexistuje v současných monitorovacích nástrojích jednoznačná metrika, která by jednoznačně byla schopna identifikovat příčinu degradace služeb.
Aktuální stav oboru je tedy takový, že je nutná intervence Data Storage Analytika, který manuálně vyhodnotí řadu výkonnostních charakteristik v klíčových uzlech Big Data úložiště. Každou takovou charakteristiku lze považovat pouze za izolovanou indicii, nikoliv však za komplexní informaci identifikující zdroj problému. Teprve až know-how specialisty umožní tyto izolované informace propojit do jednoho obrazu identifikujícího řetězec příčinných souvislostí.
Identifikace příčiny problému je tak v praxi tím nejnáročnějším bodem scénáře reakce na incident. V okamžiku, kdy je problém identifikován, tak ze samotné jeho identifikace pak vyplývá scénář reakce.
Příklad: pokud je identifikován jako problém přetížení datových médií z důvodu aktivity uživatelů, je zřejmé, že řešením je buď omezení objemu aktivity uživatelů, nebo navýšení výkonu datových médií, což se realizuje navýšením jejich počtu.
Řešení společnosti 3S.cz a VUT založené na algoritmech strojového učení si tedy primárně klade za cíl velmi rychle identifikovat příčinné souvislosti, které v rámci Big Data úložiště vedly k degradaci kvality služeb a zastoupit tak pozici „Data Storage Specialisty“ v rámci reaktivního scénáře řešení zotavení z tohoto incidentu.
Monitoring klíčových perimetrů Big Data úložiště
Monitorování úložiště může pomoci vyhodnotit:
- Úložná kapacita musí zajistit odpovídající zdroje pro optimální výkon
- Stav a výkon portů zařízení, logických jednotek, řadičů, fyzických disků a skupin disků
- Hustota IO provozu na skupinách disků
- Zpomalení na fyzických discích během akcí čtení / zápisu
- Který externí host generuje nejvyšší počet požadavků
- Analýza fronty požadavků čekajících na zpracování
Software pro monitorování úložiště poskytuje úroveň viditelnosti, která umožňuje správcům zaujmout proaktivní přístup k předvídání, diagnostice a řešení problémů v prostředí úložiště, což v konečném důsledku zlepšuje zážitek koncového uživatele díky lepšímu výkonu aplikace.
Umělá inteligence pro identifikaci chyb
Řešení společnosti 3S.cz a VUT Brno využívá algoritmů umělé inteligence pro identifikaci potenciálně problematických situací Big Data úložiště.
Architektura řešení je založena na třech fázích:
- V první fázi uživatel označkuje pomocí aplikačního GUI situace, které považuje za incident zhoršení kvality služby Big Data úložiště. Pro zpřesnění podkladů umělé inteligence lze zároveň označit situace, které považuje za bezproblémové a také situace, které k danému incidentu nemají žádnou relevanci
- Následně proběhne trénování umělé inteligence. V této, časově náročnější fázi, si umělá inteligence vytvoří matematický model, který má vztah k sledovanému incidentu
- Takto natrénovaná umělá inteligence je schopna z kontinuálně přicházejících informací (performace statistiky Big Data úložiště) těžit informace o pravděpodobnosti možnosti daného incidentu
V rámci celkového ověření funkčnosti systému byla na vybraných datech natrénována umělá inteligence pro 2 druhy nestandardního chování. Výsledné monitory byly nasazeny a ověřeny na dalších nezávislých validačních datech. Aktuální výsledky jsou zobrazeny na hlavní stránce aplikace spolu s predikcí budoucího stavu chování systému a následným zobrazením problémových částí diskového pole.
Predikovaná míra pravděpodobnosti chyby
Přesnost predikce pravděpodobnosti výskytu chyby byla vyhodnocena podle původního označení testovacích dat (byly zde vyznačeny druhy chyb v definovaných dnech). Tato přesnost byla spočtena jako podíl počtu správně klasifikovaných dní a počtu všech analyzovaných dní. Každý den byl vyhodnocen jako nestandardní, pokud predikovaná chyba byla větší než 0,5. Pokud byla chyba menší než 0,5 byl takovýto den označen jako standardní. Výsledná přesnost byla u prvního monitoru 95% a u druhého 93%. Tím je ověřena funkčnost navrženého řešení.
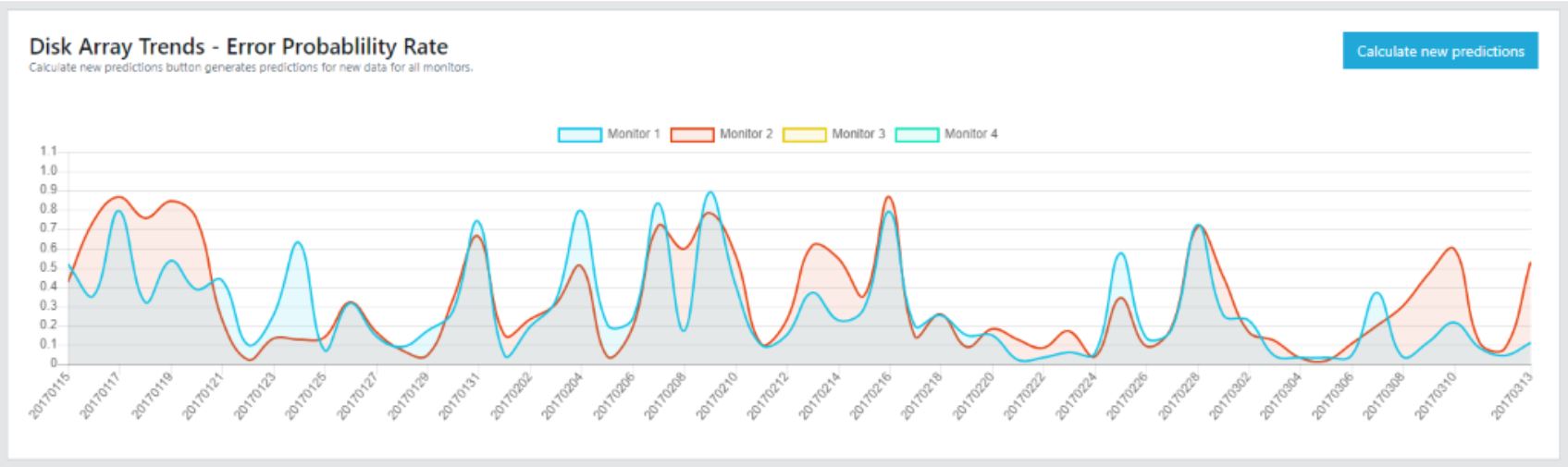
Podle predikovaných hodnot jednotlivých monitorů je provedena analýza odhadu budoucího stavu diskového pole každý monitor (monitor = situace incidentu na kterou je umělá inteligence trénována). Tento odhad je spočten s pomocí algoritmu lineární regrese, který byl vybrán na základě provedených experimentů vzhledem ke konzistenci výsledků a spolehlivosti na dostupné trénovací sadě.
Grafické znázornění predikování budoucích stavů
Podle posledního predikovaného stavu je určeno jestli se jedná o normální stav, výstrahu, nebo nebezpečí. Tento stav je určen na základě hodnoty predikovaného výskytu chyby. Pokud je hodnota větší než 0,5 jedná se o výstražní stav, pokud je hodnota větší než 0,85 jedná se o stav nebezpečí. Normální stav je pro hodnoty menší než 0,5. Aplikace je vytvořená pro natrénování až čtyř monitorů, v případě že není monitor natrénován je zobrazen zašedlý obdélník s nápisem N/A (not available - nedostupné).
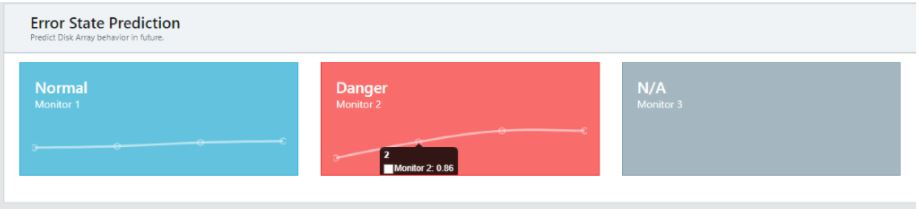
V grafech typ stavu indikován příslušným textem a barevným označením (normální modře, výstraha – žlutě, nebezpečí - červeně).
Závěr
Systém je navržen jako komplexní analytický nástroj. Kromě zobrazení a výčtu dostupné hardwarové konfigurace diskového pole umožňuje analýzu logovacích souborů pomocí algoritmů umělé inteligence. Po natrénování monitorů vybraných problémů pomocí optimalizovaných algoritmů na příslušný typ dat a potenciální velikost datové množiny má uživatel k dispozici automatický kontrolní systém monitorující pravděpodobnost výskytu chybového stavu.
Kromě kontroly chyby dle aktuální konfigurace systém dále predikuje budoucí potenciální chybové stavy a s předstihem uživatele upozorňuje na nutnost řešení případného problému. Pro tento případ systém prezentuje logovací soubory s výskytem chyby pro snadnou lokaci problému a případné řešení.
Systém byl navržen dle specifikací a odborných požadavků vycházejících z dlouholetých zkušeností s obsluhou diskových polí. Následně byla provedena studie požadavků zákazníků a poznatky byly do systému implementovány. Tímto byl vytvořen kompletní systém, který reaguje na požadavky trhu a umožňuje uplatnit automatizační schopnosti umělé inteligence pro zvýšení konkurenceschopnosti jeho uživatelů.