Specialized Section
HOW TO CHOOSE DISK ARRAY – CHAPTER 1
22.09.2015, 10:13
We are pleased and grateful for many responses to the published articles in our magazine ENTERPRISE on the topic of choice of disk arrays. And because our readers and clients are our inspiration we are now bringing you this popular series online.
It is not so long ago since the time when companies needed generally units of TB for functioning of their IT. Data volumes increase exponentially and these days we often deal with typical company needs of tens or hundreds of TB.
In light of investment the storage of such a volume of data represents one of the biggest investments. And legitimately – whereas all other infrastructure may be quite easily replaced, choosing of wrong disk storage devices may have some serious impacts like financial impact because of rigidity of chosen solution or direct financial losses originated from unavailability or whole loss of data.
How to choose data storage device accurately?
The key to the correct decision is the understanding of merits of technologies and considering the important parameters.
AUTOMATED TIERING
First of all it is necessary to consider the volume of data we are going to deal with. The larger volume, the more complicated problem the company needs to solve. The thing is to coordinate two contradictory requests – to store more and more data and to provide the access as fast as possible at the same time.
In context of that a question puts up: What latency of disk storage device is still alright and which is not? There’s no definite advice, it always depends on the individual situation and business requests. Nevertheless the generally accepted limit is till 5ms, if it is the case of databases we need to be more restrictive – till 3ms.
But let’s get back to our problem. Let’s say our company is standing in front of a task to provide storage of 50 TB of data while performance is supposed to be 50 000 Input/output operations per second or 50 000 IOPs. To solve such a request the traditional way we would need not only accordingly efficient disk array but also reasonable number of disks that would be able to “absorb” such a volume of transactions. In this case the problem would be solved by c. 200 pieces of 10 krmp disks and that leads to a very large storage device and no small investment.
However there is another solution. Statistically companies usually work only with small part of data – mostly with the newest. Other data partake of sleeping data. The older, the less it is used. The simple idea lies in the thought of storing the frequently used data to the fast disks and the “sleeping” data to NL-SAS disks. This thought is called automated tiering and it means, that the disk array works with different types of disks (with different performance and price for GB) and it can find the optimal place of storage.
The research of Gartner company is expressive – they came to the conclusion that junction of automated tiering and SSD layer of 3 % capacity of total installed capacity can support up to 80% of Input/output requests generated by infrastructure. The mentioned 3 % is necessary to acknowledge as minimum recommendation – even in context of price fall of SSD technologies it is optimal to vary from 5 % to 10 %.
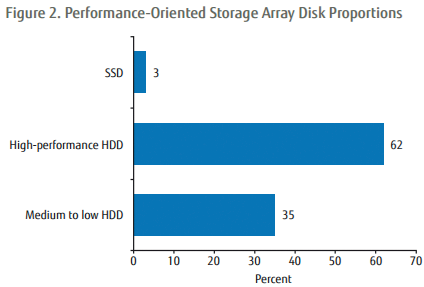
The recommendation of Gartner company for percentage distribution of capacity ratio of performance and capacity tiers for performance oriented systems.
And the first difficulty starts about here. Many producers claim they disk array contains tiering but there are many kinds of them and they may vary in its efficiency:
- LUN Tiering – the oldest one and the simplest one. It can do nothing else than to shift the whole LUN between efficiency and capacity area.
- SSD Cache – It is not actually tiering but it is only using of SSD disk as cache disk array. The most frequently used data are loaded to the SSD medium. It is a simple solution that is not programmer demanding and it can accelerate the Input/Output operations.
- Sub-LUN Tiering – The most advanced technique. It can shift pages of data within the Logical unit number (LUN) among different tiers of disk array. It can automatically tell according to the number of accesses which pages are used often and it transfers them to the fast disks (i.e. SSD or SAS RAID10). On the contrary the pages that are used sporadically are transferred to the areas with lower price for GB.
Let’s take stick to the Sun-Lun Tiering. No producers’ Sun-Lun Tiering can shift individual bytes but it works with the blocks of data – so called ”page” by reason of internal overhead. And this is the aspect the producers differ in and there is number of rumours. The biggest rumour is that smaller page means finer granularity and better efficiency of tiering. The truth is that the volume of transferred pages within a tiering the producer chooses in accordance to the options of the disk array architecture. And that’s why we meet with the size of 1 GB of page on one hand (and that is a lot) and with the size of 512 kB on the other hand. For instance the Enterprise disk array HUS-VM of Hitachi can thanks to the strong enterprise controller and size of cache use larger size of block, 42 MB to be specific. The using of reasonably large blocks in case of Tiering is eligible because it minimizes the internal overhead (loss of performance) of these functions. The using of larger blocks requires efficient controller with high permeability of GBs and cache so it could process these blocks of data without any impact on server operating. Some rival systems are limited with low performance and so they need to use small blocks i.e. 512 kB that radically boost tiering overheads, longer response time and essentially degrade total efficiency of disk system.
In the next chapter we are going to pay attention to the topic of Disk Arrays Architecture.