Sekcja specjalistyczna
TIERING W MACIERZY
23.11.2015, 10:30
Tiering należy rozumieć jako system, który rozpozna stopień wykorzystywania różnych danych oraz zapisuje je na różne typy nośników o różnej wydajności i cenie. Sensem takiego działania jest wyciągnąć z nośników dyskowych to najlepsze – z SSD wydajność a z klasycznych dysków ich dobrą cenę za jednostkę zapisanej pojemności.
Macierz nie pracuje z plikami, ale z blokami danych. Z bloków jest stworzony plik aż na poziomie systemu operacyjnego – na przykład znanego NTFS. Pomimo to, aby macierz mogła zadecydować, gdzie najlepiej zapisać dane, tak informacje od systemu plikowego nie są jej potrzebne.
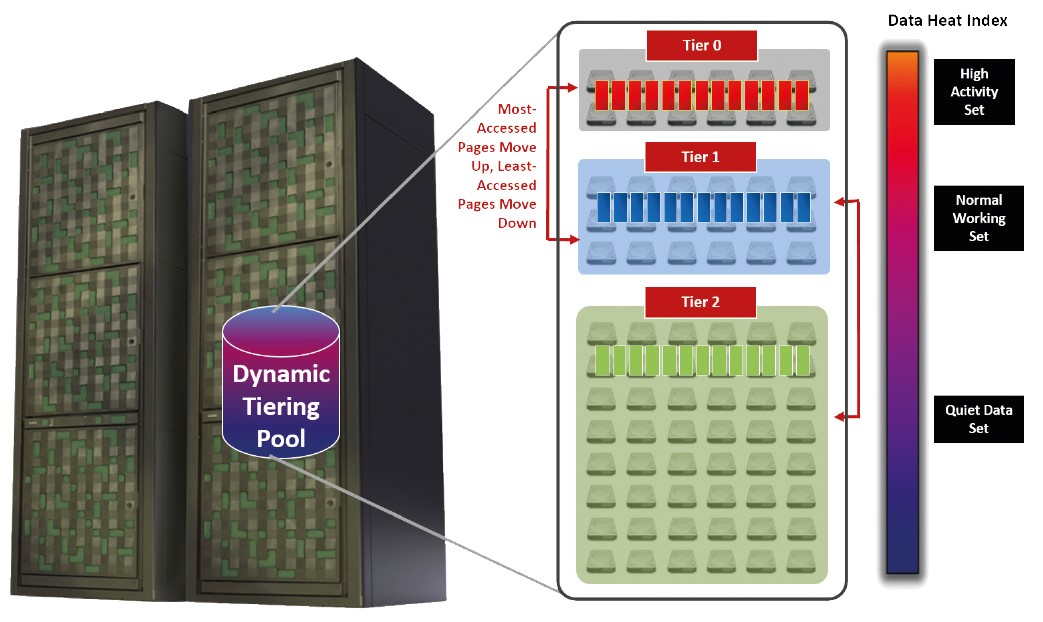
Klucz, który się wykorzystuje w celu rozpoznania, gdzie zapisać dane, to tak zwany „Heat Index“.
Macierz sama monitoruje, jak często serwery przystępują do poszczególnych bloków danych. Bloki, które są często używane, czyli „High Activity Set“, są przenoszone na szybkie nośniki, a odwrotnie mało używane bloki, czyli „Quiet Data Set“, są przenoszone na przykład na dyski NL-SAS.
Z punktu widzenia serwera wszystko przebiega transparentnie. To, na jakich nośnikach macierz przechowuje dane, serwer „nie widzi”.
W związku z tym, że się pracuje nie na poziomie pliku, ale na poziomie bloku, może się stać, że z punktu widzenia serwera mogą być części nawet jednego pliku zapisane na różnych nośnikach. W praktyce często się to stawa.
Przykład mogą stanowić obszerne pliki bazy danych systemu ERP (Enterprise Resource Planning). Jest prawdopodobne, że najczęściej używane części bazy danych będą związane z aktualnym rokiem podatkowym. Im dalej pójdziemy w historię, tym częstotliwość wykorzystywania danych będzie spadać. W tym przypadku tiering i kilka SSD/Flash może w zasadniczy sposób poprawić potencjał wydajności macierzy.
KIEDY TIERING NIE DZIAŁA?
Tiering sam w sobie nie potrafi zdziałać cudów i nie może przyspieszyć działania macierzy. Jedynie może znaleźć najbardziej efektywne umieszczenie danych na podstawie faktu, jak często się z nich korzysta. Niestety w tym też jest jego pięta Achillesa. Aby tiering mógł coś optymalizować, muszą istnieć dane, których się używa częściej od pozostałych. Ale co się stanie w sytuacji, kiedy ze wszystkich danych korzystamy równie często?
Przykładem może być baza danych e-shopu, gdzie użytkownicy do wszystkich produktów podchodzą prawie tak samo często.
Niech już mówimy o technologii Fast Cache czy Automatic Tiering, tak w obu przypadkach będzie algorytm macierzy bezradny.
Dlatego uwaga na uproszczenie typu „nasz system będzie posiadał wysoką wydajność, dlatego że tam są SSD”. To jest marketingowy skrót, który nie musi obowiązywać w każdej sytuacji.
„SŁABE MIEJSCE” TIERINGU - BACKUP
Istnieją sytuacje, kiedy działanie serwerów może algorytm FastCache czy Tieringu zmylić tak, że na wydajne i drogie nośniki „przecisną” dane, które by tam wcale nie musiały być.
Typową sytuacją jest obsługa procesów. Przede wszystkim chodzi o „nocne” procesy, jak kopiowanie, ale i np. synchronizacja oprogramowania czy replikacja. Dlatego jest korzystne, jeśli w ustawieniach Bering politik jest możliwe zakazać w niektórych pasmach czasowych, aby praca serwerów miała wpływ na funkcjonowanie tieringu.
REALNY PRZYKŁAD
Następujący przykład opisuje realną sytuację ze średnio wielkiej firmy. Była wykorzystana macierz HUS 130 oraz 3 fizyczne serwery z VMware wirtualizacją. Wewnątrz wirtualnego środowiska pracuje więcej niż dziesiątka serwerów, które spełniają zwykłe firmowe zadania – systemy ekonomiczne, systemy informatyczne, systemy obecności w pracy, serwery pocztowe, udostępnianie CIFS itd. Każdy y tych systemów wymaga szeregu bazy danych. W tym konkretnym przypadku to MS SQL, natomiast system pocztowy to MS Exchange. Tierowany pool jest złożony z 1,4 TiB SSD pojemności i 14,4 TiB pojemności na 18 x 900 GB 10krpm dyskach. Ta oto firma tworzy średnio 7.000 transakcji za sekundę, w szczycie nawet ponad 20 000 IOPs.
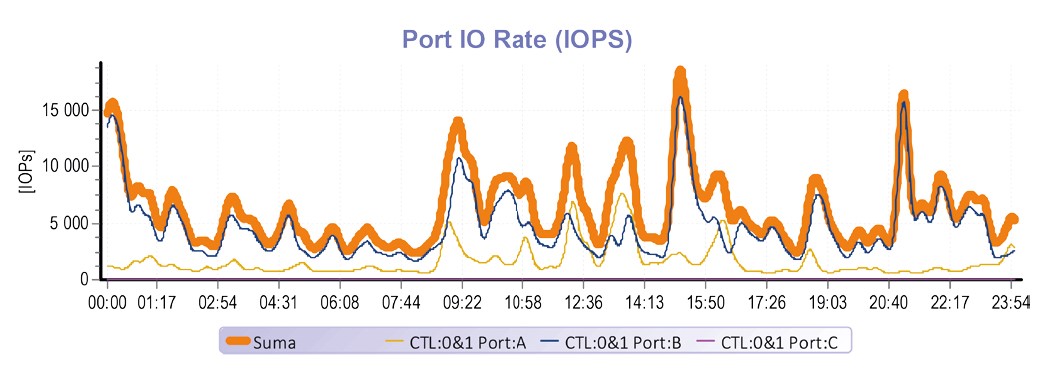
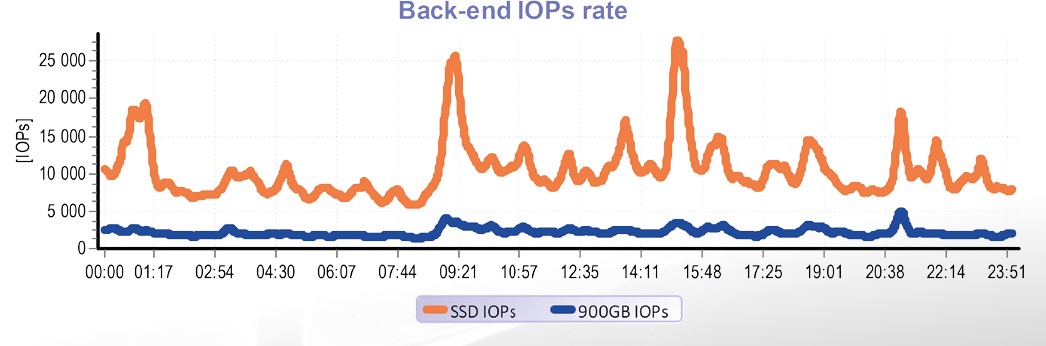
W tym konkretnym przypadku tiering zadziałał absolutnie wiarygodnie. Nawet stosunkowo mała ilość SSD pojemności w połączeniu z inteligentnym algorytmem tieringu była w stanie „wychwycić” 82% wszystkich procesów spowodowanych serwerami.
WNIOSKI
W powyżej opisanym konkretnym przypadku tylko 4 % SSD pojemności zdołało obsłużyć 82 % procesów. To oznacza, że automatyczny tiering w pełni spełnił oczekiwania. Ale trzeba pamiętać o tym, że tych wniosków nie można uogólnić na wszystkie przypadki.
Wysoka skuteczność tieringu jest w tym konkretnym przypadku dana właściwościami szeregu aplikacji prowadzonych nad macierzą. Znaczącą część pojemności alokują serwer pocztowy oraz udostępniona sieć pamięci masowej – to znaczy aplikacje, dla których jest typowe, że w dominujący sposób pracują z małą objętością aktualnych danych. A właśnie ta właściwość umożliwia, aby tiering był bardzo efektywny.